🐍 Introduction
AI Snake Lab is an interactive reinforcement learning sandbox for experimenting with AI agents in a classic Snake Game environment — featuring a live Textual TUI interface, distributed architecture, and modular model definitions.
🚀 Features
- 🐍 Classic Snake environment with customizable grid and rules
- 🧠 AI agent interface supporting multiple architectures (Linear, RNN, CNN)
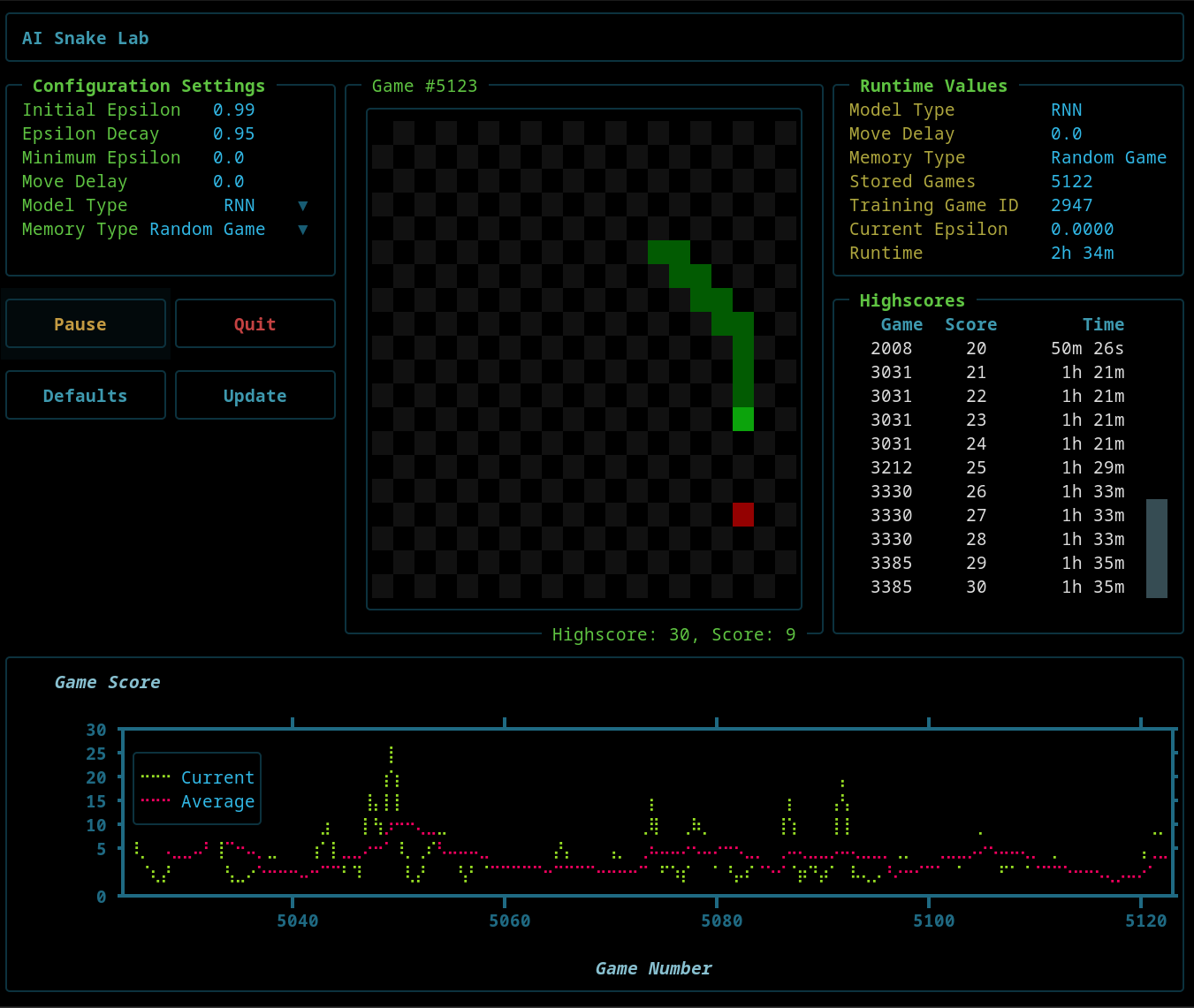
- 🎮 Textual-based simulator for live visualization and metrics
- 💾 SQLite-backed replay memory for storing frames, episodes, and runs
- 🧩 Experiment metadata tracking — models, hyperparameters, experimental features
- 📊 Built-in plotting for scores, highscores and loss
🧰 Tech Stack
| Component | Description |
|---|---|
| Python 3.11+ | The Python programming language |
| Textual | Rapid application development framework |
| SQLite3 | SQL engine database |
| PyTorch | Deep learning framework |
| Textual-Plot | Textual plotting widget |
| ZeroMQ | Messaging library |
💻 Installation
This project is on PyPI. You can install the AI Snake Lab software using pip.
Create a Sandbox
python3 -m venv snake_venv
. snake_venv/bin/activate
Install the AI Snake Lab
After you have activated your venv environment:
pip install ai-snake-lab
▶️ Running the AI Snake Lab
You need three terminals to run the AI Snake Lab. One terminal for the SimServer, one for the SimRouter, and one for the SimClient.
Lanching the simulation server:
sim-server
Lanching the simulation router:
sim-router
Launching the simulation client:
sim-client
🙏 Acknowledgements
The original code for this project was based on a YouTube tutorial, Python + PyTorch + Pygame Reinforcement Learning – Train an AI to Play Snake by Patrick Loeber. You can access his original code here on GitHub. Thank you Patrick!!! You are amazing!!!! This project is a port of the pygame and matplotlib solution.
Thanks also go out to Will McGugan and the Textual team. Textual is an amazing framework. Talk about Rapid Application Development. Porting this from a Pygame and MatPlotLib solution to Textual took less than a day.
🌟 Inspiration
Creating an artificial intelligence agent, letting it loose and watching how it performs is an amazing process. It’s not unlike having children, except on a much, much, much smaller scale, at least today! Watching the AI driven Snake Game is mesmerizing. I’m constantly thinking of ways I could improve it. I credit Patrick Loeber for giving me a fun project to explore the AI space.
Much of my career has been as a Linux Systems administrator. My comfort zone is on the command line. I’ve never worked as a programmer and certainly not as a front end developer. Textual, as a framework for building rich Terminal User Interfaces is exactly my speed and when I saw Dolphie, I was blown away. Built-in, real-time plots of MySQL metrics: Amazing!
Richard S. Sutton is also an inspiration to me. His thoughts on Reinforcement Learning are a slow motion revolution. His criticisms of the existing AI landscape with it’s focus on engineering a specific AI to do a specific task and then considering the job done is spot on. His vision for an AI agent that does continuous, non-linear learning remains the next frontier on the path to General Artificial Intelligence.
📚 Technical Docs
- Architecture
- Filesystem Layout
- Database Schema
- Constant - Definitions and Organization
- Git Commit Standards
- Git Branching Strategy
- Change Log
🔗 Links
- Patrick Loeber’s YouTube Tutorial
- Will McGugan’s Textual Rapid Application Development framework
- Dolphie: A single pane of glass for real-time analytics into MySQL/MariaDB & ProxySQL
- Richard Sutton’s Homepage
- Richard Sutton quotes and other materials.
- Useful Plots to Diagnose your Neural Network by George V Jose
- A Deep Dive into Learning Curves in Machine Learning by Mostafa Ibrahim