🧾 Introduction
This page outlines the architecture of the *AI Snake Lab software.
🧭 Client, Server and Router
The AI Snake Lab implements a client/server architecture using the ZeroMQ messaging library as a transport layer. SimServer, SimClient and SimRouter. These are three distinct processes than can be run on different machines. Multiple SimClients`** connected to the same simulation are supported.
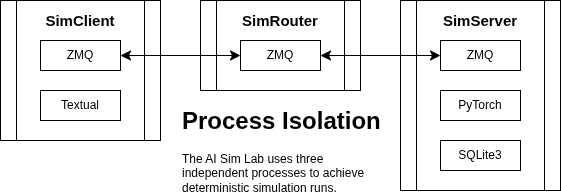
Once a simulation is running, the SimRouter and SimClients can be stopped and restarted without affecting the running simulation.
🚀 SimServer
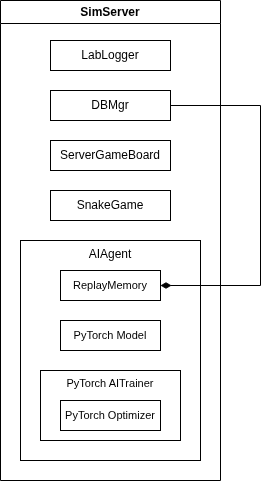
The AI Agent playing the Snake Game in a PyTorch reinforcement learning framework runs in the SimServer process. When it is launched it initializes itself. It does not start a simulation run, it only sends periodic ZeroMQ heartbeat messages to the SimRouter.
💻 SimClient
The SimClient is a Textual application. It proves a TUI for setting simulation hyper-parameters, selecting a neural network model etc. It also has buttons to control the simulation; start, pause, resume and other buttons.
Multiple SimClients, potentially running on a different machine, can connect, view and control the simulation.
When a button is pressed, the SimClient sends a message to the SimRouter which forwards it to the SimServer. The SimClient also sends regular heartbeat messages to the SimRouter.
📡 SimRouter
The SimRouter sits between SimClient and the SimServer. It tracks what is connected and routes messages appropriately. It routes all SimClient messages to the SimServer. Most of the messages from the SimServer are broadcast to all connected SimClients. However, messages are routed to a specific SimClient. These targeted server to client messages are the result of the client requesting old data when it first starts up. For example, to populate the highscores table and the loss plot.
🧙 Reinforcement Learning
The AI Snake Lab is built around a modular reinforcement learning (RL) framework designed for clarity, experimentation, and reproducibility. At its core, the system follows the classic agent–environment interaction loop: the simulation server acts as the environment, producing states and rewards, while the AI agent (running through the simulation process) observes these states, selects actions, and learns from the resulting outcomes.

🗃️ SQLite3 Database
The SimServer uses a SQLite3 backend. the ReplayMemory class stores game and game frame data there. Game score, average loss and highscore event data is also stored the the database. This data is displayed in the SimClient plots.
✨ Features
The AI Snake Lab has a wealth of featues. Some noteworthy ones are outlined below.
⚡️ Full Throttle Mode
Full throttle mode is enabled on the SimServer when there are no SimClients connected to the SimRouter. The SimRouter keeps track of the number of SimClients that are connected and sends that count to the SimServer. When the count is zero, the SimServer removes sets the move delay to zero and stops collecting and sending simulation data to the SimRouter.
The SimServer does continue to collect historical data (e.g. game score data). When a client connects again, it provides this historical data, allowing the SimClient TUI to catch up and display it.
When the SimServer sees that the client count is greater than zero, it automatically switches off full throttle mode.
The simulation runs about three times faster when full throttle mode is enabled.
🔄 Dynamic Training
The Dynamic Training checkbox implements an increasing amount of long training that is executed at the end of each epoch. The AIAgent:train_long_memory() code is run an increasing number of times at the end of each epoch as the total number of epochs increases to a maximum of MAX_ADAPTIVE_TRAINING_LOOPS, which is currently 16 according to the calculation shown below:
if self.dynamic_training():
loops = max(
1, min(self.epoch() // 250, DAIAgent.MAX_DYNAMIC_TRAINING_LOOPS)
)
else:
loops = 1
while loops > 0:
loops -= 1
self.train_long_memory()
🧩 Epsilon N
The Epsilon N class, inspired by Richard Sutton’s The Bitter Lesson, is a drop-in replacement for the traditional Epsilon Greedy algorithm. It instantiates a traditional Epsilon Greedy instance for each score. For example, when the AI has a score of 7, an Epsilon Greedy instance at self._epsilons[7] is used.
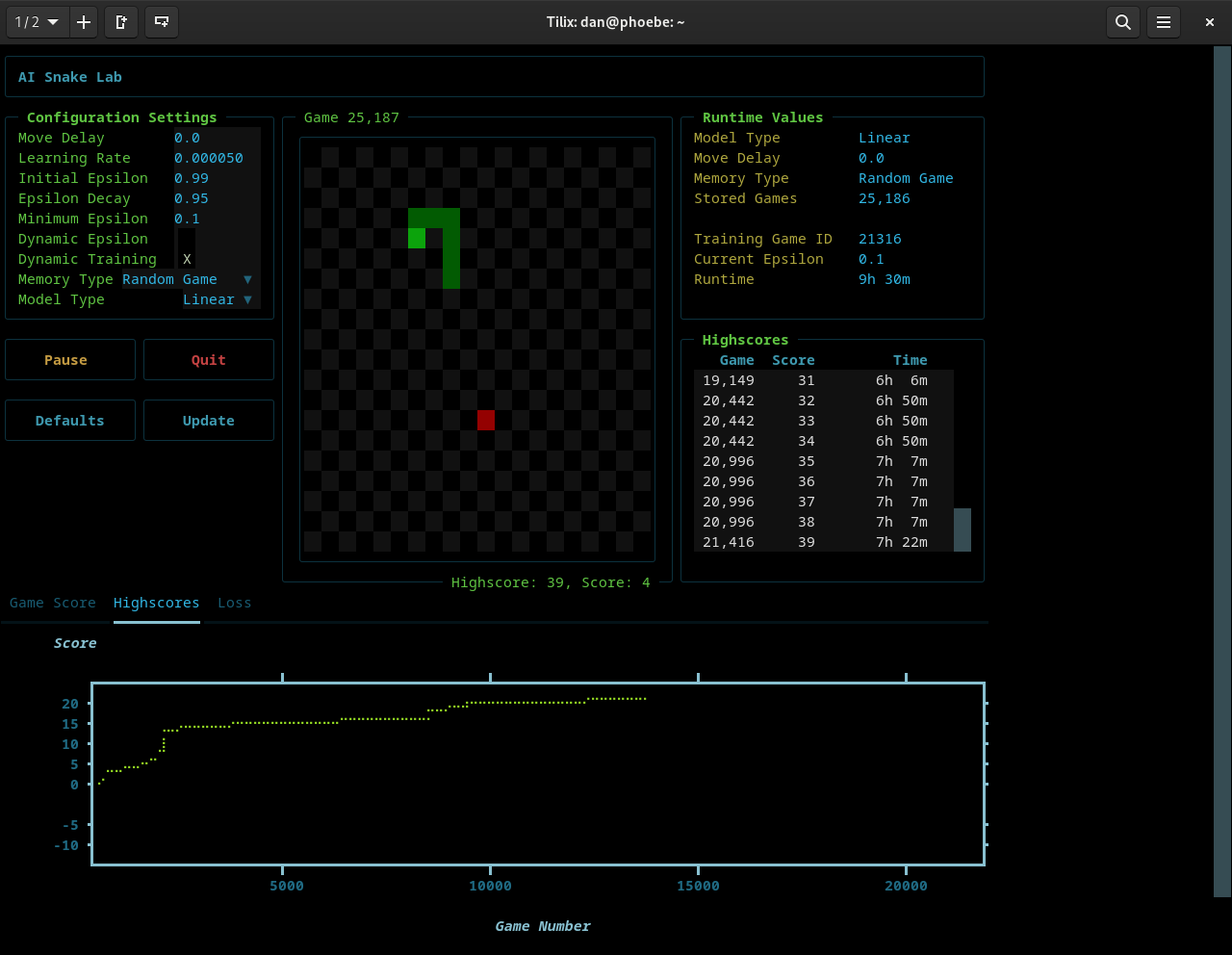
The screenshot below shows the Highscores plot with the traditional, single instance Epsilon Greedy algorithm and with Dynamic Training enabled. The single-instance epsilon algorithm quickly converges but shows uneven progress. The abrupt jumps in the high score line indicate that exploration declines before the AI fully masters each stage of play.
The next screenshot shows the Highscores plot without Dynamic Training enabled and with the Epsilon N being used. By maintaining a separate epsilon for each score level, Epsilon N sustains exploration locally. This results in a smoother, more linear high-score curve as the AI consolidates learning at each stage before progressing.
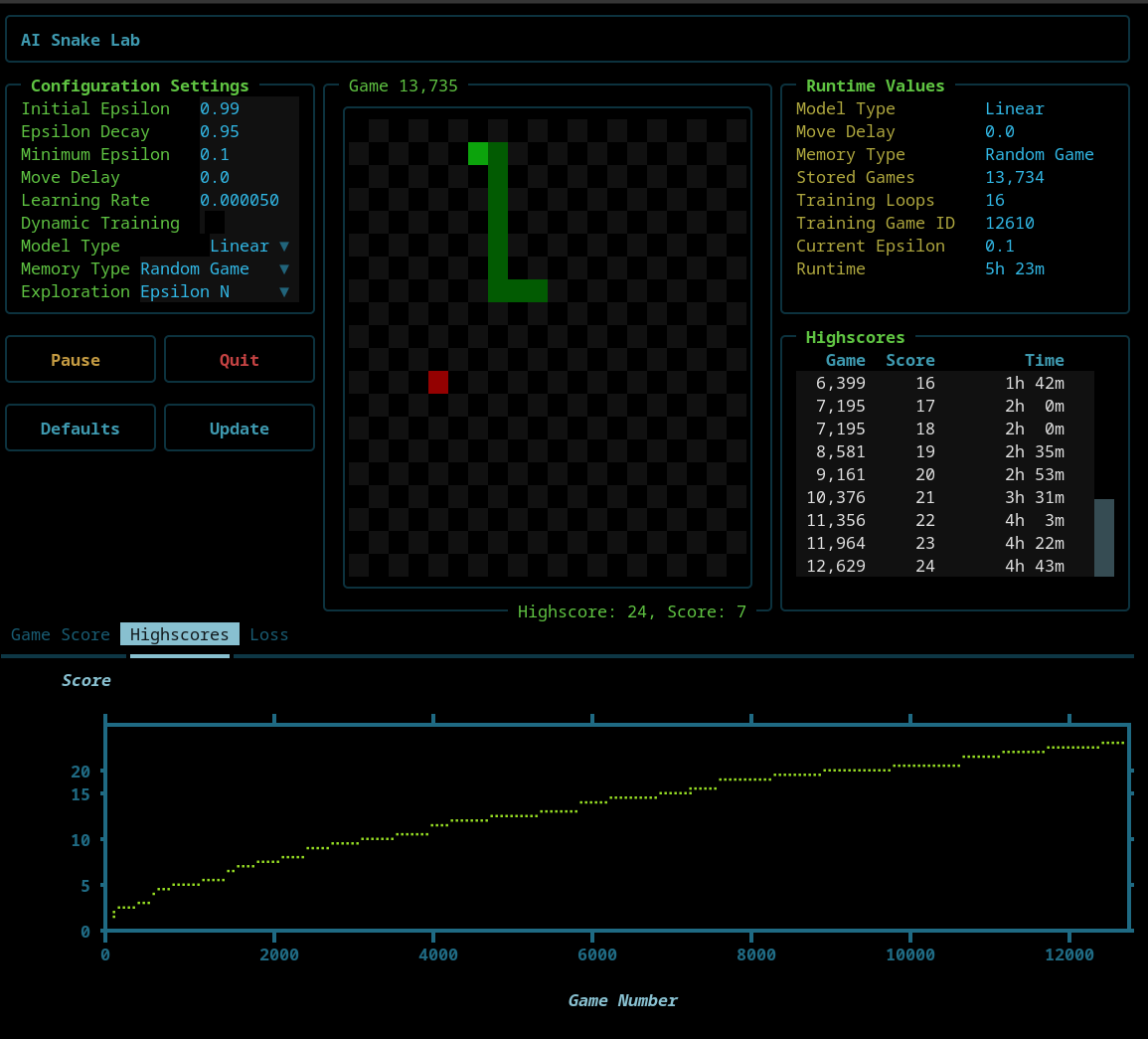
As shown above, the traditional Epsilon Greedy approach leads to slower improvement, with the highscore curve flattening early. By contrast, Epsilon N maintains steady progress as the AI masters each score level independently.